Con il termine intelligenza artificiale (o IA, dalle iniziali delle due parole) si intende generalmente l'abilità di un computer di svolgere funzioni e ragionamenti tipici della mente umana.
L'intelligenza artificiale è una disciplina dibattuta tra scienziati e filosofi, la quale manifesta aspetti sia teorici che pratici.
Nel suo aspetto puramente informatico, essa comprende la teoria e le tecniche per lo sviluppo di algoritmi che consentano alle macchine (tipicamente ai calcolatori) di mostrare un'abilità e/o attività intelligente, almeno in domini specifici.
Uno dei problemi principali dell'intelligenza artificiale è quello di dare una definizione formale delle
funzioni sintetiche/astratte di
ragionamento,
meta-ragionamento e
apprendimento dell'uomo, per poter poi costruire dei modelli computazionali che li concretizzano e realizzano ( in modo "
goal-oriented").
L'origine del termine
L'espressione "Intelligenza Artificiale" (Artificial Intelligence) fu coniata nel 1956 dal matematico americano John McCarthy, durante uno storico seminario interdisciplinare svoltosi nel New Hampshire. Secondo le parole di Marvin Minsky, uno dei "pionieri" della I.A., lo scopo di questa nuova disciplina sarebbe stato quello di "far fare alle macchine delle cose che richiederebbero l'intelligenza se fossero fatte dagli uomini".
Storia
I primi passi
In tal senso la storia ha inizio nel XVII secolo quando Blaise Pascal (scienziato, scrittore e filosofo francese) inventa la cosiddetta "Pascalina" per aiutare il padre, incaricato dall'amministrazione fiscale della Normandia di eseguire un difficile lavoro di calcolo. La macchina era capace di eseguire automaticamente addizione e sottrazione; questa "macchina aritmetica" fu la capostipite dei calcolatori ad ingranaggi.
In età vittoriana Charles Babbage creò macchine calcolatrici a rotelle: "The difference engine" (la macchina delle differenze)[1] riusciva a fare calcoli differenziali ed arrivò a progettarne una intelligente che però, per problemi tecnici, non riuscì mai a funzionare, avrebbe dovuto essere programmata con schede perforate, un po' come accadde in seguito con i primi calcolatori. Le schede perforate, cartoncini forati a seconda della necessità, furono ampiamente usate per esempio per il funzionamento dei telai Jacquard, di pianole meccaniche, quindi dei primi calcolatori. Hermann Hollerith (statistico U.S.A. di origine tedesca) ideò le schede perforate applicate a calcolatrici attorno al 1885; questo sistema fu usato per la prima volta per i calcoli relativi all'11° censimento U.S.A., nel 1891. Il sistema meccanografico adottato da Hollerith riscosse tale successo da indurlo a fondare la Tabulating Machine corporation. In seguito i calcolatori furono molto usati dai militari per regolare il tiro dell'artiglieria.
La rivoluzione informatica
Se la teoria dell'IA evolve indipendentemente dai progressi scientifici, le sue applicazioni sono fortemente legate agli avanzamenti della tecnologia informatica. Infatti, solo nella seconda metà del XX secolo è possibile disporre di dispositivi di calcolo e linguaggi di programmazione abbastanza potenti da permettere sperimentazioni sull'intelligenza.
La struttura dei calcolatori viene stravolta con la sostituzione dei "relè", usati per i primi calcolatori elettromeccanici, con le "valvole" o tubi elettronici. Nel 1946 nasce ENIAC (Electronic Numerical Integrator And Calculator), concepito come calcolatore moderno nel '45 da John von Neumann; faceva l'elaborazione a lotti (batch) nell'ordine di migliaia di informazioni al minuto. La programmazione avveniva comunque tramite schede.
La seconda generazione di computer si ha nei '60, "The time sharing", sistemi basati sulla divisione di tempo e quindi più veloci; più terminali, soprattutto telescriventi, sono collegati ad un calcolatore centrale". L'innovazione in questo periodo sta nel passaggio dalle valvole ai transistor.
A quell'epoca i programmi erano fortemente condizionati dai limiti dei linguaggi di programmazione, oltre che dai limiti di velocità e memoria degli elaboratori. La svolta si ha proprio tra gli anni '50 e '60, con linguaggi di manipolazione simbolica come l'ILP, il LISP e il POP.
Il punto di svolta
Un punto di svolta della materia si ha con un famoso articolo di Alan Turing sulla rivista Mind nel 1950. Nell'articolo viene indicata la possibilità di creare un programma al fine di far comportare un computer in maniera intelligente. Quindi la progettazione di macchine intelligenti dipende fortemente dalle possibilità di rappresentazione simbolica del problema.
Il test di Turing -così viene chiamata la condizione che la macchina dovrebbe superare per essere considerata intelligente- è stato più volte superato da programmi e più volte riformulato, tanto che queste teorie hanno ricevuto diverse confutazioni. Il filosofo Searle ne espose una famosa, chiamata "la stanza cinese".
Nello stesso anno dell'articolo di Turing sull'omonimo test per le macchine pensanti, Arthur Samuel presenta il primo programma capace di giocare a Dama, un risultato molto importante perché dimostra la possibilità di superare i limiti tecnici (il programma era scritto in Assembly e girava su un IBM 704) per realizzare sistemi capaci di risolvere problemi tradizionalmente legati all'intelligenza umana. Per di più, l'abilità di gioco viene appresa dal programma scontrandosi con avversari umani.
Nel 1956, alla conferenza di Dartmouth (la stessa conferenza a cui l'IA deve il suo nome), viene mostrato un programma che segna un'altra importante tappa dello sviluppo dell'IA. Il programma LT di Allen Newell, J. Clifford Shaw e Herb Simon rappresenta il primo dimostratore automatico di teoremi.
La linea seguita dalla giovane IA si basa quindi sulla ricerca di un automatismo nella creazione di un'intelligenza meccanica. L'approccio segue essenzialmente un'euristica di ricerca basata su tentativi ed errori oltre che investigare su tecniche di apprendimento efficaci.
Verso l'IA moderna
Secondo le parole di Minsky, dopo il 1962 l'IA cambia le sue priorità: essa dà minore importanza all'apprendimento, mentre pone l'accento sulla rappresentazione della conoscenza e sul problema ad essa connesso del superamento del formalismo finora a disposizione e liberarsi dalle costrizioni dei vecchi sistemi.
"Il problema della ricerca efficace con euristiche rimane un presupposto soggiacente, ma non è più il problema a quale pensare, per quanto siamo immersi in sotto-problemi più sofisticati, ossia la rappresentazione e modifica di piani" (Minsky, 1968).
I punti cardine di questa ricerca sono gli studi di Minsky sulla rappresentazione distribuita della conoscenza, quella che viene chiamata la "società delle menti", e il lavoro di John McCarthy sulla rappresentazione dichiarativa della conoscenza. Quest'ultima viene espressa formalmente mediante estensioni della logica dei predicati e può quindi essere manipolata facilmente. Con i suoi studi sul "ragionamento non monotono" e "di default", McCarty contribuisce a porre gran parte delle basi teoriche dell'IA.
Il punto di vista psicologico non viene assolutamente trascurato. Ad esempio il programma EPAM (Feigenbaum e Feldman, 1963) esplora la relazione tra memoria associativa e l'atto di dimenticare. Alla Carnegie Mellon University vengono sperimentati programmi per riprodurre i passi del ragionamento, inclusi eventuali errori.
L'elaborazione del linguaggio naturale sembra essere un campo destinato a un rapido sviluppo. La traduzione diretta di testi porta però ad insuccessi che influenzeranno per molti anni i finanziamenti in tale campo. Malgrado ciò, viene dimostrato abbastanza presto che si possono ottenere buoni risultati in contesti limitati.
I primi anni '70 vedono lo sviluppo dei sistemi di produzione, ossia dei programmi che sfruttano un insieme di conoscenze organizzate in base di dati, attraverso l'applicazione di regole di produzione, per ottenere risposte a domande precise. I sistemi esperti hanno sostituito i sistemi di produzione per via delle difficoltà incontrate da questi ultimi, con particolare riferimento alla necessità di fornire inizialmente la conoscenza in forma esplicita e la poca flessibilità delle regole di produzione. Questi sistemi, di cui Dendral è il più rappresentativo, mostrano le enormi possibilità offerte da un efficace sfruttamento di (relativamente) poche basi di conoscenza per programmi capaci di prendere decisioni o fornire avvisi in molte aree diverse. In pratica l'analisi dei dati è stata razionalizzata e generalizzata.
Si pone ora il problema del trattamento dell'incertezza, che è parte costituente della realtà e delle problematiche più comuni. Mycin introduce l'uso di "valori di certezza": un numero associato a ciascun dato e che viene calcolato per la nuova conoscenza inferita.
Malgrado ciò, le difficoltà nel trattare correttamente l'incertezza portano ad abbandonare l'uso di sistemi a regole per avvicinarsi a quella che è la moderna IA.
Caratteristiche e dibattiti filosofici
La formulazione attuale
L'IA, come viene studiata attualmente, tratta dell'individuazione dei modelli (appropriata descrizione del problema da risolvere) e degli algoritmi (procedura effettiva per risolvere il modello).
Questa formulazione viene studiata con differenti sapori e con approcci differenti. Ognuno dei due aspetti (modellizzazione o algoritmico) ha via via maggiore o minore importanza e varia lungo uno spettro abbastanza ampio.
Creare un computer pensante
Le attività e le capacità dell'Intelligenza Artificiale comprendono:
La domanda al centro del dibattito sull'intelligenza artificiale è fondamentalmente una sola: "I computer possono pensare?"
Le risposte sono varie e discordi, ma perché abbiano un senso bisogna prima determinare cosa significhi pensare. Ironicamente, nonostante tutti siano d'accordo che gli esseri umani sono intelligenti, nessuno è ancora riuscito a dare una definizione soddisfacente di intelligenza; proprio a causa di ciò, lo studio dell'IA si divide in due correnti:
- la prima, detta intelligenza artificiale forte, sostenuta dai funzionalisti, ritiene che un computer correttamente programmato possa essere veramente dotato di una intelligenza pura, non distinguibile in nessun senso importante dall'intelligenza umana. L'idea alla base di questa teoria è il concetto che risale al filosofo empirista inglese Thomas Hobbes, il quale sosteneva che ragionare non è nient'altro che calcolare: la mente umana sarebbe dunque il prodotto di un complesso insieme di calcoli eseguiti dal cervello;
- la seconda, detta intelligenza artificiale debole, sostiene che un computer non sarà mai in grado di eguagliare la mente umana, ma potrà solo arrivare a simulare alcuni processi cognitivi umani senza riuscire a riprodurli nella loro totale complessità.
Rimanendo nel campo della programmazione "classica", basata su linguaggi simbolici e lineari, in cui la grande velocità di calcolo dei processori moderni supplisce alla carenza di parallelismo, sicuramente assume una posizione dominante l'AI debole, in quanto si può facilmente constatare come un computer elabori una serie di simboli che non comprende e che si limiti ad eseguire i suoi compiti meccanicamente.
Bisogna tuttavia riconoscere che, con la diffusione sempre maggiore di reti neurali, algoritmi genetici e sistemi per il calcolo parallelo, la situazione si sta evolvendo a favore dei sostenitori del connessionismo.
A detta di alcuni esperti del settore, però, è improbabile il raggiungimento, da parte di un computer, di una capacità di pensiero classificabile come "intelligenza", in quanto la macchina stessa è "isolata" dal mondo, o, al massimo, collegata con esso tramite una rete informatica, in grado di trasmettergli solo informazioni provenienti da altri computer. La vera "intelligenza artificiale", perciò, potrebbe essere raggiungibile solo da robot (non necessariamente di forma umanoide) in grado di muoversi (su ruote, gambe, cingoli o quant'altro) ed interagire con l'ambiente che li circonda grazie a sensori ed a bracci meccanici. Spesso, difatti, anche nell'uomo, l'applicazione dell'intelligenza deriva da qualche esigenza corporea, perciò è improbabile riuscire a svilupparne un'imitazione senza un corpo.
Inoltre, finora, nel tentativo di creare AI, si è spesso compiuto un errore che ha portato i computer all'incapacità di applicare il buonsenso e alla tendenza a "cacciarsi nei pasticci". L'errore consiste nel non considerare a sufficienza il fatto che il mondo reale è complesso e quindi una sua rappresentazione lo sarà altrettanto. Non solo sarà complessa, ma sarà anche incompleta, perché non potrà mai includere tutti i casi che il robot potrà incontrare. Perciò, o immettiamo nel cervello artificiale una quantità enorme di informazioni corredate da altrettante regole per correlarle (il che originerà, probabilmente, un vicolo cieco logico alla prima difficoltà incontrata), oppure lo mettiamo in condizione di imparare. La chiave dell'AI, sembra proprio essere questa: l'imitazione della sua analoga naturale, tenendo ben presente l'importanza dei processi evolutivi nello sviluppo delle caratteristiche morfologiche e comportamentali di un individuo e nella formazione di ciò che viene definito "senso comune".
Vincenzo Tagliasco, ricercatore al Laboratorio integrato di robotica avanzata presso la facoltà di Ingegneria dell'università di Genova, fa notare che nell'evoluzione delle macchine intelligenti si è cercato di saltare intere generazioni di macchine più modeste, ma in grado di fornire preziosi stimoli per capire come gli organismi biologici interagiscono con l'ambiente attraverso la percezione, la locomozione, la manipolazione. Ora c'è chi segue un approccio più coerente: prima di insegnare a un robot a giocare a scacchi, è necessario insegnargli a muoversi, a vedere, a sentire. Insomma, anche nel robot intelligente occorre creare una "infanzia", che gli consenta di mettere a punto autonomi processi di apprendimento e di adattamento all'ambiente in cui si troverà ad agire. È necessario quindi riprodurre due evoluzioni parallele: una che da costrutti semplici porti alla produzione di macchine sempre più complesse e sofisticate, un'altra, tutta interna alla vita del singolo automa, che lo faccia crescere intellettualmente, dandogli modo di apprendere, da solo o sotto la supervisione umana, le nozioni necessarie al suo compito ed alla formazione di un'autonomia decisionale.
Questo modo di procedere è sintetizzato in una disciplina di recente sviluppo come branca dell'IA. Stiamo parlando di Artificial Life - A.I., la cui prima proposta si deve a Chris Langton. Comprendendo in tale disciplina la robotica avanzata si può anche introdurre lo studio della robotica evolutiva. Il tutto fa uso di simulazioni software e hardware di quello che potrebbe essere l'ambiente e gli organismi primitivi che in tale ambiente interagiscono, si riproducono ed evolvono verso popolazioni sempre più complesse e sofisticate ma senza necessità dell'intervento umano.
L'intelligenza artificiale, continuando lungo le attuali direttrici di sviluppo, diverrà sicuramente un'intelligenza "diversa" da quella umana, ma, probabilmente, comparabile a livello di risultati in molti campi in cui è necessario applicare capacità di scelta basate su casi precedenti, nozioni generali e "ragionamento".
È invece molto difficile immaginare un computer in grado di filosofeggiare ed esprimere concetti e dubbi riguardo l'origine o il senso della vita. Il terribile computer-dio del racconto La Risposta di Fredric Brown non è altro - per fortuna - che fantascienza.
La versione fantascientifica
Nelle opere di fantascienza l'intelligenza artificiale è un tema ricorrente, come semplice strumento o come protagonista della storia. In generale è presentata come computer avanzati o robot.
Nel primo caso rientrano ad esempio Multivac, presente in alcuni racconti di Isaac Asimov, paragonabile ai moderni sistemi di grid computing, e HAL 9000 del film 2001 Odissea nello spazio. Pensiero Profondo nella Guida galattica per autostoppisti è una intelligenza artificiale capace di fornire la risposta alla domanda fondamentale sulla vita, l'universo e tutto quanto.
I robot senzienti sono anch'essi un classico. Nell'ipotesi che le macchine possano man mano diventare più simili agli esseri umani, gli autori hanno ipotizzato macchine dalla enorme capacità di calcolo e dotate di personalità. I "robot positronici" come il robot Robbie del film Il pianeta proibito, Marvin l'androide paranoico, C1-P8 di Guerre stellari e Data di Star Trek sono solo alcuni esempi tra i più noti.
Queste macchine si distinguono dai semplici robot per una personalità spiccata, resa possibile da un'intelligenza artificiale estremamente evoluta.
Un altro caso è invece Skynet del ciclo cinematografico di Terminator, in cui viene presentato come un sofisticatissimo insieme di networks alla difesa costruiti dagli Stati Uniti verso la fine della guerra fredda, e che comanda un esercito di cyborgs di classe T-800, T-1000 e TX.
Nel ciclo di Dune di Frank Herbert, invece, il tema delle intelligenze artificiali costituisce ciò che si potrebbe definire un sacrilegio: migliaia di anni prima gli avvenimenti di Dune, le macchine pensanti avevano ridotto alla schiavitù l'umanità, e a seguito della Jihad Butleriana, occasione in cui si impongono le scuole di pensiero quali la Gilda Spaziale, i Mentat, il Bene Tleilax e le Bene Gesserit, il primo comandamento della nuova religione del nascente impero della Casa Corrino è: "Non costruirai mai una macchina somigliante a una mente umana.".
Applicazioni principali
Attualmente questi sono i principali algoritmi dell'intelligenza artificiale
Voci correlate
Collegamenti esterni







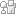









![[1]](http://www.ftldesign.com/Babbage/DSCN2416e.jpg){kind=link}